|
|
In this laboratory assignment we will consider the following:
A. Doubly Linked Lists
B. Circular Linked Lists
C. Dummy head Nodes
D. Multi-Linked Lists
In this lab session we will study some of the more common variations of linked list structures including lists with more than one pointer field and the usage of "dummy" nodes in the implementation of linked list structures. There are many linked list problems that can be "easily" solved by using one or more of these variations of linked structures. For example, consider the set of problems in which we must start at the head and traverse the list until we get one node short of a specified place: "delete the last node" or "insert before the node pointed to by p." For many problems, for example, the inefficiency of list traversal can be removed at the expense of a "backward pointer" or using a doubly linked list structure rather than a singly linked list.
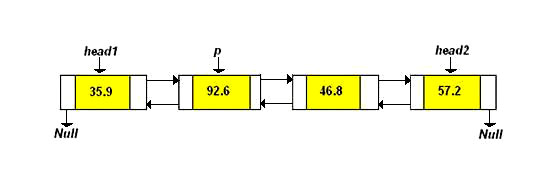
A linked list in which each node has 2 pointers: a forward pointer (a pointer to the next node in the list) and a backward pointer (a pointer to the node preceding the current node in the list) is called a doubly linked list. Here is a picture:
This list has two special pointers called head1 and head2 so that the list
may be traversed beginning at either end of the list.
Before we look at some sample uses, let's learn to manipulate these doubly linked lists. Imagine we want to insert a new node after (to the right of) the node pointed to by p. Here is a code segment:
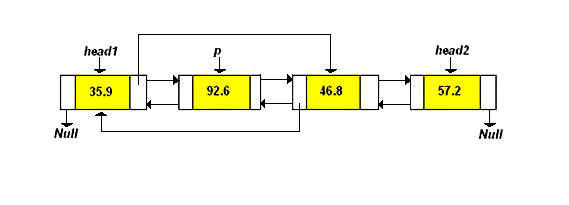
Note that this algorithm will have problems if p points at the last node in the list.Node* q; q = new Node; q->data = newData; q->next = p->next; // make q point where p did to right q->next->prev = q; // make node to right of q point back at q q->prev = p; // make q point at p on left p->next = q; // make p point at q on right
Here is a picture showing how to delete the node pointed to by p (from the original list given above).
The increased efficiency of certain operations from a doubly linked
list should be obvious as should the increase in space required for the
extra pointers. Is it worth the extra space? That depends.
If you have plenty of space and must have efficient insertion and deletion,
the answer is yes. If you need to move in both directions in
the list, then you have little choice. Take, for example, a doubly
linked list of lines in a document that may be kept by a text editor.
The following denotes how each node should appear:
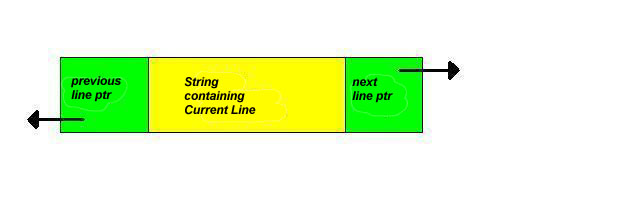
To move backward and forward through the document (as it appears on
the screen ) and insert or delete lines, a doubly linked list is ideal.
With the cursor on the current line (stored in a pointer "current"),it is easy
to move up one line (current = current->prev) or down one line
(current = current->next). With a singly linked list this is possible
but probably too slow.
All of our examples so far have required that a linked list have a beginning node and an ending node: the beginning node was a node pointed to by a special pointer called head and the end of the list was denoted by a special node that had a NULL pointer in its next pointer field. If a problem requires that operations need to be performed on nodes in a linked list and it is not important that the list have special nodes indicating the front and rear of the list, then this problem should be solved using a circular linked list. A singly linked circular list is a linked list where the last node in the list points to the first node in the list. A circular list does not contain NULL pointers. Note the example of a singly linked circular list below:
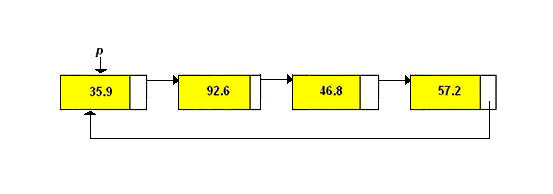
A good example of an application where a singly linked circular list should be used is a timesharing problem solved by the operating system. In a timesharing environment, the operating system must maintain a list of present users and must alternately allow each user to use a small slice of CPU time, one user at a time. The operating system will pick a user, let him/her use a small amount of CPU time and then move on to the next user, etc. For this application, there should be no NULL pointers unless there is absolutely no one requesting CPU time.
One of the problems in dealing with pointer based ordered lists is writing code to take care of special cases. For example, if we wish to insert a node in an ordered linked list, we MUST take care of the special case of inserting this node in the beginning of the list. This is a special case because if a node is inserted into the beginning of the list, the pointer indicating the beginning of the list, head, must be changed. Similarly, if we wish to delete a particular node, we must again also write code to handle the special case of deleting the first node in the list.
To avoid the special case problems involved in inserting and deleting
nodes, programmers often use a dummy node in the list. A dummy
header node is a node that always points to the beginning of the list
or has a NULL pointer field if the list is empty. This node is called
a dummy node since it does not contain data included in the list.
This node is permanent (is never deleted) and always points to the first
node in the list. To eliminate the need for special structures, it
is preferred that the dummy node be set up using the same type of nodes
as the data nodes in the list. Here is an example of a singly linked
list with a dummy header node:
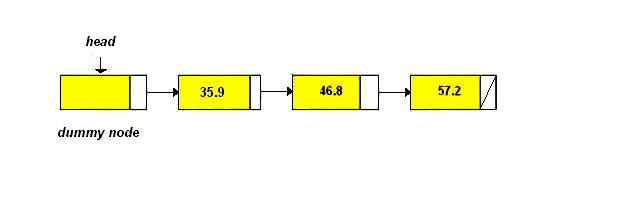
Now, let's determine how to insert a node pointed to by the pointer p into an ordered singly linked list. If the singly linked list is ordered, we must first determine where the node should be placed in the list. This is accomplished by setting up auxillary pointers, prev and current, moving these pointers down the list until prev is pointing to a node that should precede the node pointed to by p and current should be pointing to the first node that should succeed the node pointed to by p. The question is: How should prev and current be initialized? If a singly linked list with a dummy header node is used, then prev and current should be initialized to head and to head->next respectively.
A list can have two pointers without having a backward pointer. For instance,
we may want to keep a set of data ordered on more than one "key". A key
is a unique data item included in a record that distinguishes one record
from all other records included in the list. Suppose we want to be
able to access customer accounts in order by account number (integer) and
by customer name (string). We can in fact have one list that
is ordered both ways. We need two pointer fields. Each node of the
list will have the form:
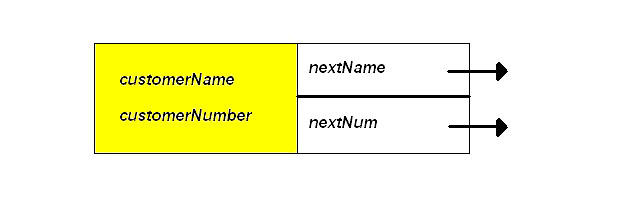
Now, let's assume that we have a class called MultiListClass and that we wish to implement this list with a dummy header node. Here is an example list that implements the multi-linked list:
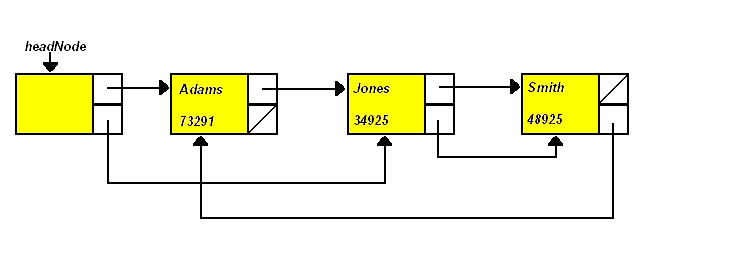
Insertion and deletion are more complicated in multi-linked lists. Below is a function we have written that inserts the new node into the linked list that is ordered alphabetically by the customer name. We use the notation from above.
// Algorithm for insertion into multi-linked list with two links. //This is the structure of nodes in the list struct Node { TypeData name; //Person's name TypeInt number; //Person's account number TypePtr nextNum; //Pointer to next record by account number TypePtr nextName; //Pointer to next record by name }; //Function to insert a node into a linked list ordered by customer name void MultiListClass::insertNameList(TypePtr p) //IN: p points to the node to be inserted into the list { //initialize prev and current TypePtr prev = head; TypePtr current = head->nextName; //move prev and current until current is NULL or //current is pointing to a node that contains a name //that is larger than the name to be inserted into the list while (!insertName(current,p)) { prev = current; current = current->nextName; } //insert the node between prev and current prev ->nextName = p; p->nextName = current; }
Now, we also need a function that will insert the node into the list ordered by the customer account number:
//Function to insert a node into a linked list ordered by customer //account number void MultiListClass::insertNumList(TypePtr p) { //Initialize prev and current TypePtr prev = head; TypePtr current = head->nextNum; //Move prev and current until current is NULL or is pointing //to a node that contains a customer number that is larger //than the customer number contained in the node to be inserted while (!insertNum(current, p)) { prev = current; current = current->nextNum; } //Insert the node between prev and current prev ->nextNum = p; p->nextNum = current; }
We have implemented this insert algorithm in inlab19.cpp. It is used to build a multi-linked list with two links. Copy this source file to your account along with the data file inlab19.dat.
Submit the required log files by using the command
$ handin lab19log lab19ex7.log