ADLB is a software library designed to help rapidly build scalable
parallel programs.
The name (pronounced adlib) is the acronym for Asynchronous
Dynamic Load Balancing. However, ADLB does not achieve scalability
solely by load balancing. It also includes some features that exploit
work-stealing as well.
Indeed, we sometimes use the phrase
instantaneous load balancing via work-stealing
to describe ADLB.
ADLB will be available under the same license arrangement as MPICH2.
There are features of ADLB that are reminiscent of a variety of other
systems, e.g. Linda.
However, ADLB is significantly different and unique in a number of ways.
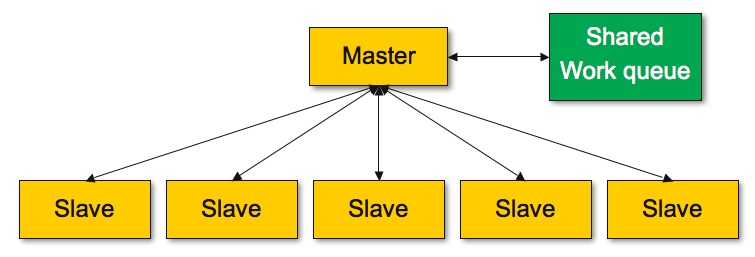
When one begins to ponder an approach to parallelization of a given
algorithm, a natural alternative to consider is a Master/Slave Algorithm,
much like depicted here:
However, one is forced to accept the fact that such an approach is not likely to be very scalable due to the probable bottleneck caused by slave ranks trying to access data on the shared queue which is managed by the master.
What one really wants is an approach where the shared queue is easily
accessible to all ranks without need to go through an arbiter process.
For example:
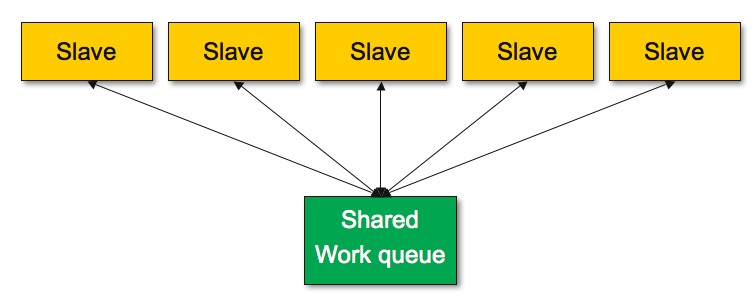
However, even in that case, it is possible for the shared queue to become a bottleneck if the shared queue requires synchronized access.
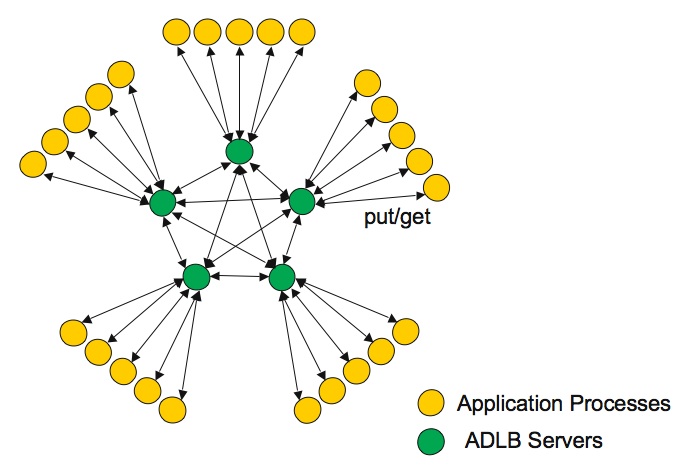
The ADLB approach to these problems is to develop a distributed shared
queue. This distributed queue logically appears as a single queue to
all the app ranks. Portions of the queue are kept at each of several
server ranks. These servers are solely responsible for managing the queue
and do not participate in the app's computation. The servers share
information among themselves about the current state of the work queue.
When an app rank wants a piece of data, it can contact a server to help it
retrieve that data. Data can migrate to arbitrary servers depending
on memory usage, load, etc. For example:
From the user's perspective, ADLB is relatively trivial to use. Any process can simply do a Put operation to place data into a shared space, and any process can later Reserve then Get that data. Thus, the typical mode of operation is for an application to treat the shared space as a repository for work units. Arbitrary processes can add work to, or retrieve work from, the pool as needed. In support of the basic operations, there are additional provisions to provide enhanced functionality. For example, when data is Put into the shared space, it can be marked as targeted for (only reservable by) a particular rank. There are also some special operations designed to boost performance as well as to gather statistical information about a run.
ADLB assumes the presence of MPI. For example, in the current implementation, the app is responsible for performing the MPI_Init operation before ADLB_Init. Further, ADLB uses MPI ranks to identify processses.
Details of the ADLB API are covered more fully in a later section below. In this section, we merely present a brief overview designed to quickly give you the basic idea. ADLB consists of only a very small number of procedures to invoke. The most widely used ones are:
Currently we support an API for C and Fortran programs. Thus, below we follow the format of some of the MPI documentation providing both the C and Fortran prototypes for each function.
nservers indicates how many processes should become ADLB servers.use_debug_server indicates if the last rank should become a debug server.aprintf_flag indicates if aprintf's should print; usually used for printing internal info by adlb itself.am_server will be set to 1 if the calling process should become a server, else 0.am_debug_server will be set to true in the rank that should play that role.type_vect contains an entry for each type the app may Put. ntypes provides the length of that vector.app_comm is a new MPI communicator that processes should use
for communications instead of MPI_COMM_WORLD.
malloc_hwm specifies the max amount of memory the app
would like for the server to use. This can be useful if the server
shares memory with some app ranks. Also, the server uses it to set
thresholds for when to push data, etc.
periodic_log_interval specifies how often, in seconds,
we wish to have adlb log periodic stats. If 0.0, then NO logging is done.
work_buf points to the work itself.work_len is the length of the work in bytes.target_rank can be -1 (wild card) if the work is not targeted
to any particular rank. If >= 0 it will not permit any other rank to reserve
the work.answer_rank is used by some applications to indicate which
rank is interested in the results of computations from this work.work_type is set by the app but must be one of those registered
at Init.work_prio is determined by the app. ADLB makes a
non-exhaustive attempt to retrieve the highest priority work later.
req_types is a vector of up to 4 types (currently) that are
ORed together. ADLB will return the highest priority work of one of those
types that it can find (quickly).work_type is set to the type of work actually reserved.work_prio is set to the priority of the work reserved.work_handle is set to a value that is used to retrieve the
work later.work_len can be used to allocate buffer space before doing a
Get operation.answer_rank tells which rank to send answers to (or reserve
them for); not necessarily used by all apps.
You can view the ADLB trunk from read-only svn:
here.
Or, you can download it by executing this command in a terminal window:
svn co http://svn.cs.mtsu.edu/svn/adlbm/trunk adlbm
We also try to keep an up-to-date tgz here:
here.
The companion software (DMEM) can also be downloaded here:
here.
Or, you can download it by executing this command in a terminal window:
svn co http://svn.cs.mtsu.edu/svn/dmem/trunk dmem
On a "typical" linux system, you should be able to just do the usual:
./configure
make
Note that since ADLB is still very much in development mode, there is currently no install target. You have to either work in the ADLB directory, or move the libraries to a directory where you want them, or create a Makefile elsewhere which points to the ADLB libraries.
For other systems, there are a few pre-defined arg sets that you can supply to configure. For example, on our sicortex, we use:
./configure --with-config-args=sicortex
This causes the file configargs/sicortex.cfg to supply
arguments to the configure script. You can create your own customized
configure options files specific to your own environment.
There are a number of small test programs that are targets in the Makefile. You might want to build and run the nq program (nqueens). For example:
make nq
mpiexec -l -n 2 nq
mpiexec -l -n 10 nq -q -n 9 -nservers 2
The first execution of nq prints the 2 solutions to a 4x4 nqueens
puzzle. The program stalls for about 5 seconds, because nq
halts only when ADLB has determined that it has reached exhaustion,
i.e. no more processes are going to do any Put operations because
they are all waiting for Reserves. At present, ADLB prints
quite a bit of information at the beginning and end of each run.
We will reduce the output later when we enter a production mode.
The second execution of nq runs 10 processes. Two of them are ADLB
servers, and the remaining 8 are nq app ranks. The -n argument to nq
says to do a 9x9 board puzzle.